Lessons learned from csblogs.com v1.0

In April this year, Danny Brown and I began re-writing csblogs.com. While version 2.0 looks and acts the same, a lot has changed under the hood. Here are some of the things we’ve learnt along the way.
MongoDB wasn’t for us
While I didn’t have much of a hand in this choice, mongoose.js was easy to develop with at the early stage of development. We later realised MongoDB was not good for relational data, which we had between blog posts and bloggers (and in the future, maybe organisations). For 2.0, we’ve moved to SQL and sequelize.js for our data storage.
How to write CSS properly
CS Blogs was my first proper website outside of tweaks to others projects and university work. Looking back at my CSS now, I can see I didn’t quite get it, or know how LESS nesting worked. For example:
#head-content {
max-width: 800px;
margin: 0px auto;
padding: 0px 25px;
position: relative;
#nav-bg {
display: none;
}
}#nav-bg doesn’t need any nesting, and I made it very difficult to override any attributes. I had also set unnecessary attributes that wouldn’t affect the element it was set on.
Though the site might look identical, I’ve redone all the LESS in SCSS, and fixed the mistakes I made. Here are the number of lines for each of the LESS files in 1.0:
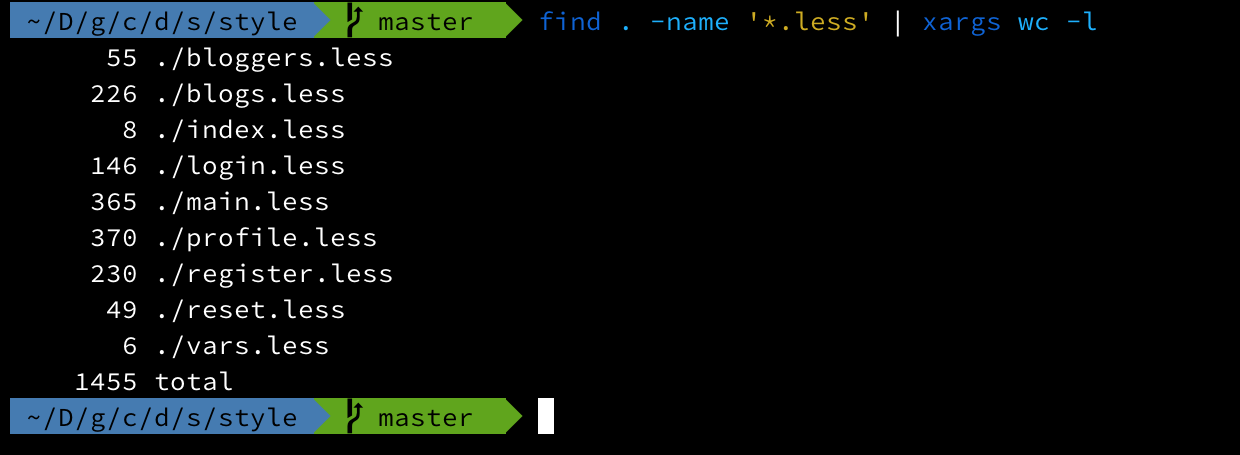
And the same for the SCSS in 2.0:

The new code is 200 lines lighter, 269 if you ignore the addition of self-hosted fonts. This means fewer bytes to send the users when they load the page.
We’re also linting both JS and SCSS now, meaning fewer mistakes and a more consistent style between coders.
JavaScript tools move on fast
Babel was only a few months old when we started CS Blogs, and we definitely weren’t writing with ES2015/16/17. Version 2.0 is built with Babel using new features like arrow functions, async/await, and module imports. Promises have been a joy to use, meaning none of this:
exports.validate = function(newBlogger, done) {
newBlogger.sanitize();
newBlogger.validate(function(errors) {
isVanityUrlTaken(newBlogger, function(taken, error) {
validateUserSubmittedUrls(newBlogger, function(brokenUrls) {
if (error) {
return done(null, null, error);
}
// etc...And a lot more of this:
export function update(properties, userId) {
const trimmedProps = trimNewUserJSON(properties);
return validateNewUserSchema(trimmedProps)
.then(validateNewUserFeedLoop)
.then(props => updateUserInDatabase(userId, props));
}Separate your codebase
In version 1.0 of our web-app we put all our website serving and API endpoints in a single respository. We even had all our routes in a single file. In 2.0 we now have separate *-routes.js files for each concern of our app.
We have now split the API and website into two repositories so there is no confusion over how to read and manipulate user data. Whatever you can do on the website, anyone can write their own app to do.
It’s not all bad…
We did make some good decisions in version 1.0. The design of the website has held up, and I wrote it to be responsive to different screen sizes which is still as valid as ever.
We used Passport.js to connect with GitHub, Stack Exchange, and Wordpress as authentication providers. This means we had to handle very little secure user information — it was all done by those trusted services. It also makes it really easy to migrate users from MongoDB as their identifier is their login service ID. Login with the same service as in 1.0 and it just works.